Hola a todos muy buenos días; continuando con el curso de MIRIADA X "Encontrando tesoros en la red (4.ª edición)", veremos hoy el tema de "El arte de buscar en la Web".
En la antigua Grecia, el filósofo Platón les decía a sus discípulos (Entre los cuales se encontraba Aristóteles):

"Si bien buscas encontrarás"

"Si bien buscas encontrarás"
Trasladando su consejo a el tema de buscar información en la Web, diríamos que para encontrar buenas respuestas hay que formular las preguntas correctas.
Antes de realizar una consulta pensemos qué es lo que deseamos encontrar y definir lo más concreto posible nuestro objetivo en una pregunta.
Pero para obtener la respuesta justa es fundamental formular nuestra pregunta en la forma más adecuada y para éso debemos ordenar los conocimientos previos que tenemos sobre el tema, aprovechar de manera eficaz esos “retazos” de información y formular una buena pregunta. Luego los diferentes elementos identificables deben ser traducidos a términos que puedan ser interpretados por un buscador. Estos términos son denominados palabras claves o descriptores.
Existen tres tipos de palabras claves:
Llevemos a la práctica lo anterior y hagamos una investigación sobre el desarrollo de aplicaciones con el framework PhoneGap.
Pregunta general: ¿Qué manuales del desarrollo de aplicaciones con el framework PhoneGap puedo encontrar en la Internet?
Campo temático: PhoneGap, desarrollo, aplicaciones, código, programación
Problema específico: Manual, tutorial, libro, pdf
Referencias autorales: Cualesquier autor
Para realizar la búsqueda de información utilizaremos el buscador académico de Google, a fin de enfocarnos en la información recopilada en sitios de expertos, profesores y estudiosos del tema.
El buscador académico de Google se puede accesar en el siguiente link: http://scholar.google.es/

Pero para obtener la respuesta justa es fundamental formular nuestra pregunta en la forma más adecuada y para éso debemos ordenar los conocimientos previos que tenemos sobre el tema, aprovechar de manera eficaz esos “retazos” de información y formular una buena pregunta. Luego los diferentes elementos identificables deben ser traducidos a términos que puedan ser interpretados por un buscador. Estos términos son denominados palabras claves o descriptores.
Existen tres tipos de palabras claves:
- Las palabras claves de campo temático:
Son los nombres de las disciplinas y los términos imprescindibles que no pueden dejar de estar mencionadas en un documento que habla del tema de nuestra pregunta.
- Las palabras claves de problema específico:
Son frases breves que mencionan el asunto o su núcleo problemático más específico. En realidad, no son palabras claves, sino frases específicas o expresiones claves, segmentos de texto insertos en un contexto que intentamos rescatar. Por eso es aconsejable incluir expresiones “en uso” que tengan que ver con el lenguaje que utilizamos habitualmente.
- Las palabras claves de referencias autorales:
Son nombres de autores que se encuentran directamente relacionados con el problema, y que son considerados clásicos o referentes importantes en la materia. Sirven para identificar apellidos en listas bibliográficas que no siempre incluyen el nombre del autor, por lo tanto, es conveniente incluir sólo apellidos.
Llevemos a la práctica lo anterior y hagamos una investigación sobre el desarrollo de aplicaciones con el framework PhoneGap.
Pregunta general: ¿Qué manuales del desarrollo de aplicaciones con el framework PhoneGap puedo encontrar en la Internet?
Campo temático: PhoneGap, desarrollo, aplicaciones, código, programación
Problema específico: Manual, tutorial, libro, pdf
Referencias autorales: Cualesquier autor
Para realizar la búsqueda de información utilizaremos el buscador académico de Google, a fin de enfocarnos en la información recopilada en sitios de expertos, profesores y estudiosos del tema.

El buscador académico de Google se puede accesar en el siguiente link: http://scholar.google.es/

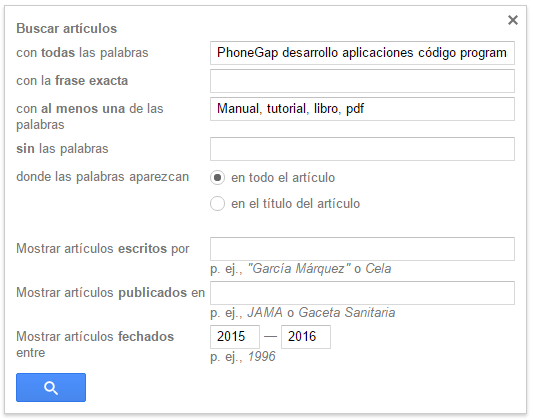
Accediendo a sus opciones de búsqueda avanzada (Esto se hace dando click en el símbolo de flecha hacia abajo, ubicado en la caja de texto del buscador),
Veremos el siguiente formulario:



Este número de resultados obtenidos es razonable si lo comparamos con el número de resultados que se suelen obtener en los buscadores convencionales, los cuales oscilan entre los 10,000 y 500,000.
Una regla en la búsqueda de información es que el número de resultados obtenidos debe oscilar entre los 10 y 150.
Si son menos de 10, se debe ampliar la consulta eliminando uno o más palabras claves.
Si son más de 150, se debe restringir la consulta agregando una o más palabras claves.
En nuestro caso vemos que debemos restringir la consulta agregando palabras claves; así que pediremos resultados que hayan sido publicados entre los años 2015 y 2016 para definir aún más lo que deseamos.
Y habiendo delimitado nuestra consulta obtenemos esta vez 105 resultados; un número menor al anterior y que cumple con el requisito del rango en la cantidad.

Y con ésto terminamos con el tema de hoy; espero que les haya resultado ilustrativo.
Que tengan un excelente día y aquí nos vemos en la próxima publicación.
Veremos el siguiente formulario:

Llenando los campos correspondientes con las palabras claves (separadas por espacios en lugar de comas) que determinamos anteriormente veremos que obtenemos 252 resultados que cumplen con los requisitos de nuestra búsqueda.

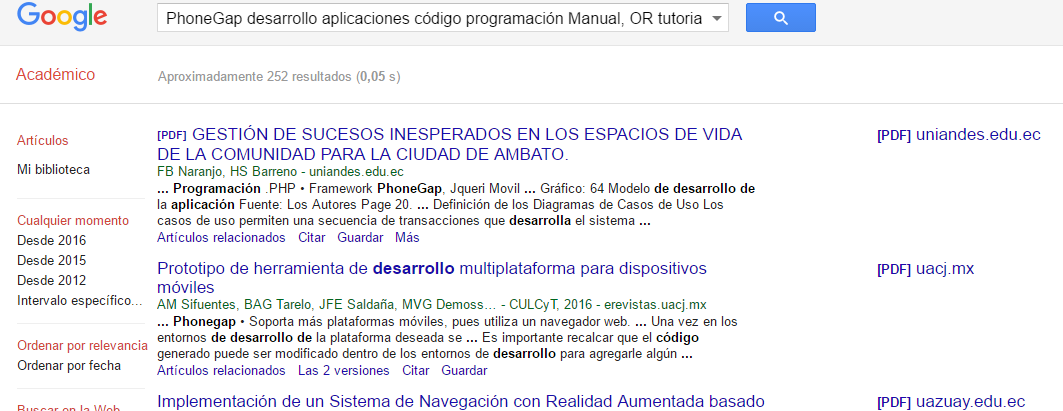
Este número de resultados obtenidos es razonable si lo comparamos con el número de resultados que se suelen obtener en los buscadores convencionales, los cuales oscilan entre los 10,000 y 500,000.
Una regla en la búsqueda de información es que el número de resultados obtenidos debe oscilar entre los 10 y 150.
Si son menos de 10, se debe ampliar la consulta eliminando uno o más palabras claves.
Si son más de 150, se debe restringir la consulta agregando una o más palabras claves.
En nuestro caso vemos que debemos restringir la consulta agregando palabras claves; así que pediremos resultados que hayan sido publicados entre los años 2015 y 2016 para definir aún más lo que deseamos.

Y habiendo delimitado nuestra consulta obtenemos esta vez 105 resultados; un número menor al anterior y que cumple con el requisito del rango en la cantidad.

Y con ésto terminamos con el tema de hoy; espero que les haya resultado ilustrativo.
Que tengan un excelente día y aquí nos vemos en la próxima publicación.




